
Een app die de verandering in levensverwachting vanuit verschillende perspectieven toont, gericht op landen
Blog
De blog bevat kleine projecten en gedachten, meningen die niet op de andere pagina’s thuishoren. De visuals of apps voor Figure Friday projecten zijn de ene keer wat meer gepolijst dan de andere keer. Het is een wekelijks terugkerend event en er is niet altijd veel tijd.

Figure Friday 2025-w44
Billboard Hot 100

Figure Friday 2025-w40
Testresultaten rekenen/wiskunde NYC, grade 3 – grade 8

Figure Friday 2025-w38
Eindejaars top3 ATP ranglijst mannen tennis

Figure Friday 2025-w37
Fictieve sales dataset met wonderlijke transacties

Figure Friday 2025-w34
Montreal Metro Incidents 2019 (jan 1) -2025 (may 1)

Experiment 4 met #plotlystudio: opnieuw grafieken recreëren.
Blogs in deze serie zijn gebaseerd op de early access preview-versie van Plotly Studio. Plotly Studio is een AI-gedreven desktopapplicatie van Plotly, ontwikkeld om het bouwen van professionele data-apps en visualisaties te automatiseren.

Plotly Studio Experiment 3: Gekleurde oppervlaktegrafieken met AC vs PY omzet per medewerker
Blogs in deze serie zijn gebaseerd op de early access preview-versie van Plotly Studio. Plotly Studio is een AI-gestuurde desktopapplicatie van Plotly, ontwikkeld om het maken van professionele data-apps en visualisaties te automatiseren.

Plotly Studio experiment 2
Blogs in deze serie zijn gebaseerd op de early access preview-versie van Plotly Studio. Plotly Studio is een AI-gestuurde desktopapplicatie van Plotly, ontwikkeld om het maken van professionele data-apps en visualisaties te automatiseren.

Plotly Studio experiment 1
Blogs in deze serie zijn gebaseerd op de early access preview-versie van Plotly Studio. Plotly Studio is een AI-gestuurde desktopapplicatie van Plotly, ontwikkeld om het maken van professionele data-apps en visualisaties te automatiseren.

Figure Friday 2025-w28
Corruption Perception Index (CPI): vergelijk regio’s en landen

Figure Friday 2025-w23
Hoeveel slechte gewoonten houden mensen erop na.

Figure Friday 2025-w22
Marvel films, verhouding tussen wereldwijde inkomsten en budget, een AI Claude-experiment.

Figure Friday 2025-w21
CO2 emissiecijfers per land, per periode.

Figure Friday 2025-w20
Dammen in de USA: is er een actieplan voor dammen waarbij een ongeluk grote gevolgen kan hebben.

Figure Friday 2025-w19
Inzicht in het proces (deelnemers en afvallers) om een TLC rijbewijs te krijgen. Een TLC rijbewijs is een rijbewijs dat je in de USA toestemming geeft voor speciaal vervoer.

Figure Friday 2025-w17
Emigratie en immigratie beweging per land, per jaar in de periode 1990-2024. De app geeft inzicht in land van herkomst of bestemming wat betreft inkomensclassificatie volgens de wereld bank.

Figure Friday 2025-w16
Een visualisatie die het percentage huishoudens in een continent of land toont, met een bepaald huisdier.

Figure Friday 2025-w15
Een app die het op basis van marketingcijfers mogelijk maakt om de “range” van verschillende elektrische auto’s met elkaar te vergelijken. Je kunt kiezen voor een verzameling Nederlandse of wereldwijde steden als uitvalsbasis.

Figure Friday 2025-w14
Een app die het mogelijk maakt om de tijden van de winnaars in verschillende roeicategorieen met elkaar te vergelijken. Daarnaast is het ook mogelijk om de winnaarstijden per jaar te vergelijken met een heatmap met temperatuur, regen en/of wind omstandigheden.
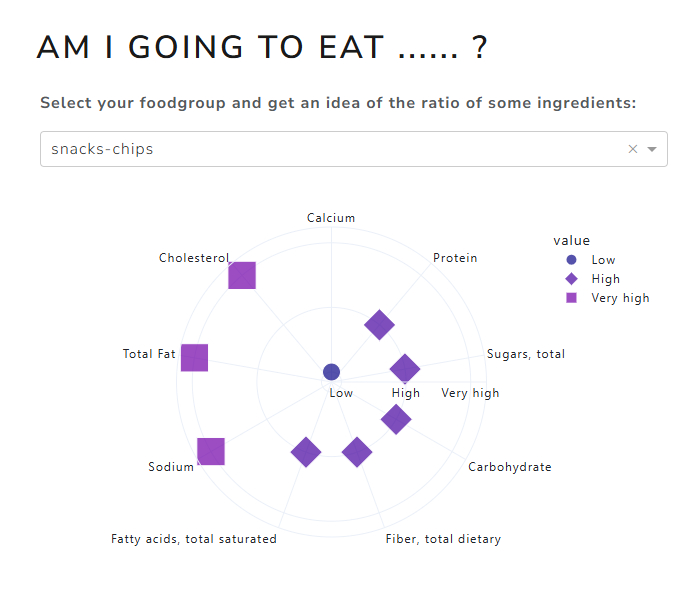
Figure Friday 2025-w13
De app geeft je een inzicht in de samenstelling van voedsel binnen een bepaalde voedselgroep, als het gaat om stoffen zoals cholesterol, suiker en meer.

IBCS experiment 3
Maandomzet per medewerker in overzicht met vergelijking zelfde periode vorig jaar.
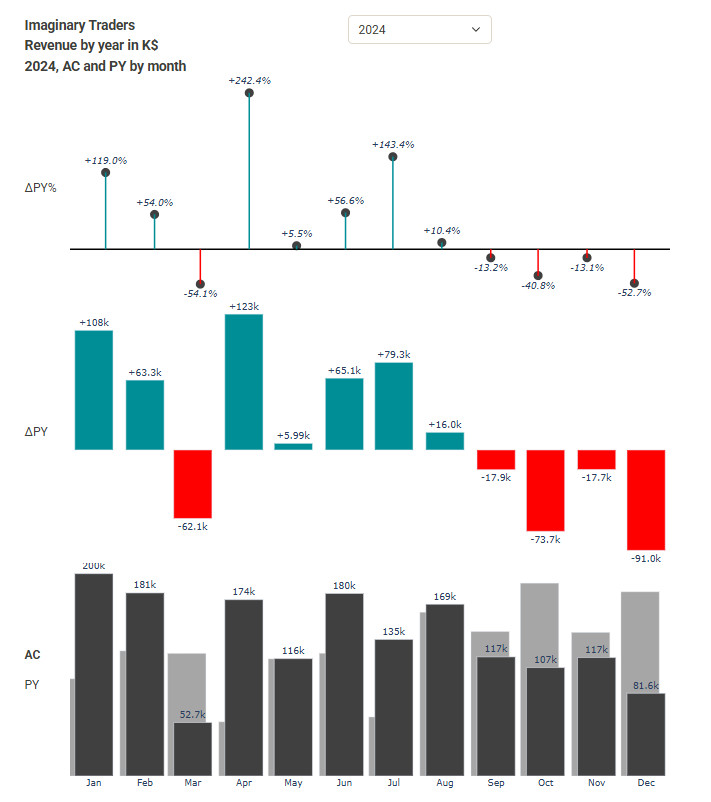
IBCS experiment 2
Jaaromzet, vergelijk met vorig jaar in $ en %


IBCS experiment 1
Actuele omzet en omzet vorige maand in $ en % op 1 scherm.








Mijn eerste AI gegenereerde afbeeldingen
Een paar weken geleden kreeg ik de kans om de plugin Imajinn AI te testen. De plugin is een product van Infinite Uploads. De plugin geeft je de mogelijkheid om in een bericht of pagina een Gutenberg Image AI Block te plaatsen dat op basis van een omschrijving die je geeft 1 of meerdere afbeeldingen …

Global sentiment analysis of my most recent tweets
Edit 7 jan. 2025, since Twitter got a new owner, this stopped working. Last Monday, I read a post on LinkedIn that said participating in data challenges is not the way to build your portfolio. I don’t quite agree with that. My father used to hurl “üben, üben, üben” (German, it means exercise a lot, by the way I am Dutch) at my head and every challenge is an exercise, if only in patience. I decided to answer the question “suppose a machine investigates whether I am a bit positive on Twitter, what would the result be“. I went for a Sentiment Analysis.
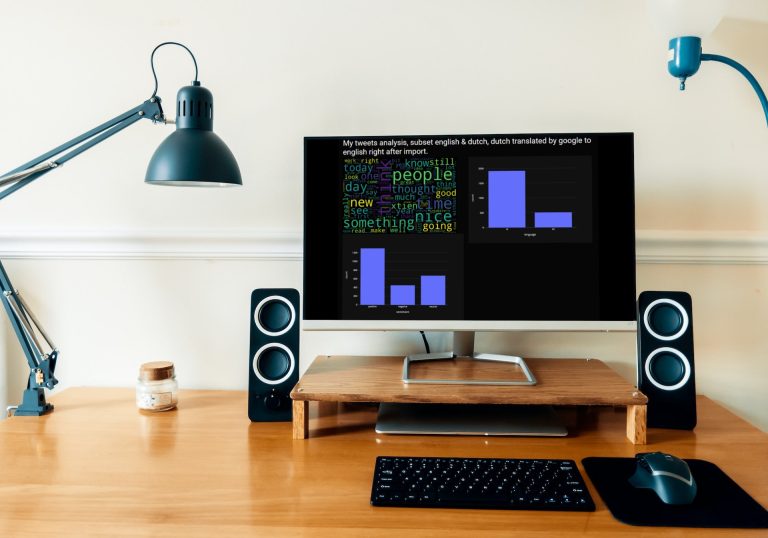
Globale sentimentanalyse van mijn tweets
Afgelopen maandag las ik een post op LinkedIn waarin stond dat meedoen aan data challenges niet de manier is om je portfolio op te bouwen. Daar ben ik het niet helemaal mee eens. Mijn vader slingerde regelmatig “üben, üben, üben” naar mijn hoofd en elke challenge is een oefening, al is het maar in geduld. Maar goed, iets anders dus. Ik besloot de vraag “stel dat een machine onderzoekt of ik wel een beetje positief ben op twitter door daar een sentiment analyse op los te laten” te beantwoorden. Mijn eigen analyse die mijn tweets indeelt in positief, negatief en neutraal moest het antwoord op de vraag geven.

Try before you error
Problem to solve: importing many files into Power BI where some are not complete and trigger an ODBC error.
While importing thousands of JSON files I bumped into the situation where some of the files weren’t following the structure and thus caused an error and the import process to stop. The files were supposed to have some general and customer information about an order and order lines structured under “lines”.

Getting to know my computer
Problem to solve: fast find occurences of a string in thousands of files on a Windows computer
The first computer I ever worked with was the Mac SE, small, heavy, loud, with a nice graphical user interface. When I decided to follow a computer class, the first screen I saw was black with a nice c:\>. I thought the computer was broken. Windows 3.1 was yet to come. I never paid much attention to all the possibilities Windows offers nowadays until a few days ago.
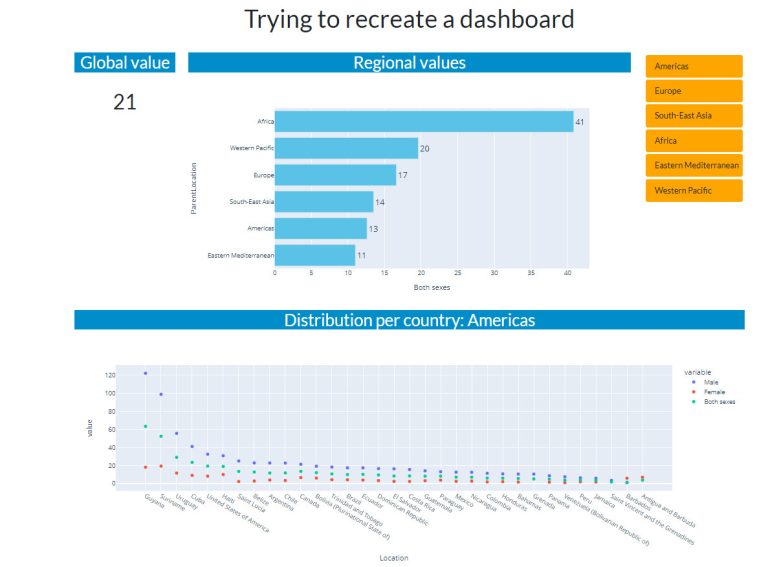
Recreate dashboard with plotly and dash
To get more experience with python I decided to recreate a dashboard I saw online. You can filter and select the data to download, I used the most recent data (2019). On the Visualisations tab (using the WHO link above) you can find the dashboard I tried to make (the second visualisation).