
Last Monday, I read a post on LinkedIn that said participating in data challenges is not the way to build your portfolio. I don’t quite agree with that. My father used to hurl “üben, üben, üben” (German, it means exercise a lot, by the way I am Dutch) at my head and every challenge is an exercise, if only in patience. I decided to answer the question “suppose a machine investigates whether I am a bit positive on Twitter, what would the result be“. I went for a Sentiment Analysis.
The answer had to be built in Python, Dash and Plotly. My current favourite configuration. The question seemed to me to be all pretty straightforward and googleable.
Below you can read about my global approach, some problems I encountered and useful links, the code is on Github. It is not a “recipe or how to” but a small report on what I did, the problems I encountered and some links I regarded as useful.
Retrieve your tweets
Before you start analysing data, it is useful to have them. To be able to retrieve data from twitter, you need to create an app on developer.twitter.com. I chose an Essential app (which is free with limitations on the number of tweets you can retrieve). You have to take those limitations seriously, after 2 days of messing around my statistic looks like this:
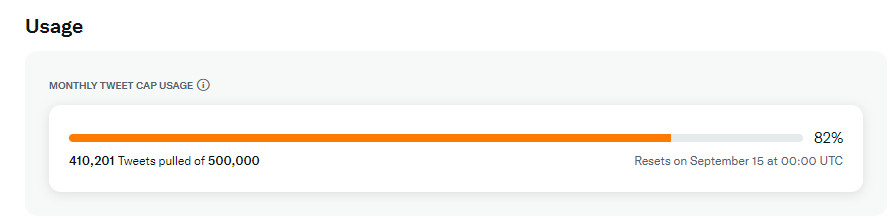
Tip: export important results in your code as .csv. For instance the result of a successful retrieval of many tweets. Use the .csv instead of calling the API over and over again as I did. Actually this is obvious but when you are like me "caught in the moment" you forget about those simple things. With a decent .csv you can continue working even if you exceed the limit. If certain steps take a long time, see below "translate with Google translate", you can also shorten the processing time by not calling the API.
Oauth and Oauth2
When you create a Twitter app, the next step is to generate the keys and tokens you need to query the Twitter API. It is not completely straight forward which keys and tokens to use. Twitter has Oauth and Oauth2 available, two ways to authorize for accessing the API. It took me a while to realize that by definition I was using Oauth2. In the twitter developer dashboard, I had the possibility to enable both, but my Essential free app could only use Oauth2. If things don’t work out in the spirit of “403, forbidden, access denied” notifications, and you start googling, keep an eye on the difference between Oauth and Oauth2.
Tweepy is not the only way
I used the Tweepy library to access the API. Twitter also has a library of its own. There are differences and the Tweepy documentation refers to the Twitter documentation every once in a while. Be aware of that when you search for answers and be aware that Twitter has different versions of it’s API, I used the v2 endpoint. Tweepy has also different documentation based on the version of the Twitter API used.
Getting as much tweets as possible
I wanted as many tweets as possible without restrictions (i.e. also all retweets, replies etc). I used get_users_tweets in combination with paginator and only processed text.
Using Twitters own library or a different retrieval method (different call, query in it, other parameters) might yield more tweets. My max. result is about 2800 tweets out of 3200 possible with my Essential app. Another reason to be satisfied with this result: to know if another approach yields more tweets you have to test and retrieve tweets, which takes time and decreases your free budget.
Useful links
Two sources helped me to solve the authorization problem and get a better understanding of paginator in Tweepy:
The sentiment of my tweets, version 1
The website of Professor Jan Kirenz, kirenz.com, is a salutary source of programming examples with concise explanations. Unfortunately, the professor can not be followed on LinkedIn or at least, I did not see the button. In my search for answers, I came across his example of a sentiment analysis with Vader and decided to follow along.
I followed the tutorial and it all worked at once, except for the sentiment histogram. I attribute this problem to loading Mathplotlib, Plotly and Seaborn at the same time, which is stupid but happened. Once the graphs were moved to Plotly, the problem disappeared. Working in the previous context means running without errors, the result did not make sense. “O my gosh, am I that shallow?”. Most tweets were ranked neutral.
Plotly has no word cloud, I wanted to keep the word cloud. Fortunately, via this link on Stackflow you can read how you can show a word cloud as a .png image on your Dash dashboard. With some small adjustments for my specific situation, it worked. [Update 18th aug. 2022: On LinkedIn Dave Gibbon made me aware of the existence of this Dash Word Cloud package, if I pick up this project again I will most certainly give it a try.]
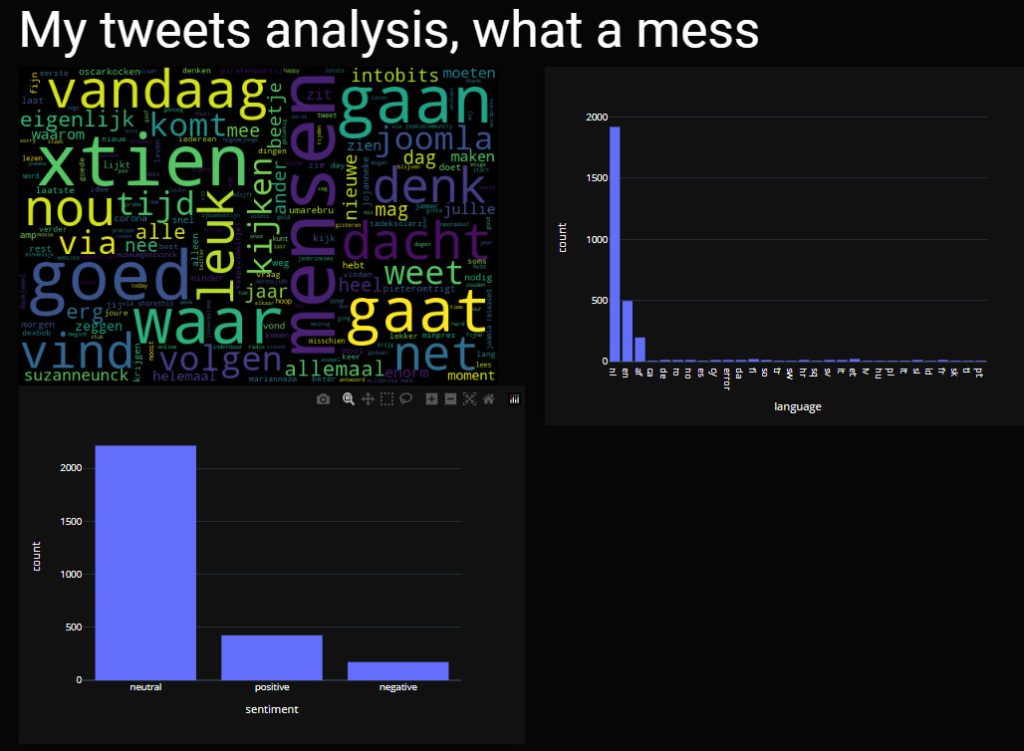
The tweets, the used languages and Vader
Vader only analyses English texts. My texts are in English and Dutch, most in Dutch. And sometimes just the result of Wordle or an emoticon.
I wanted to stay with Vader, the first step was to unleash language recognition on the tweets. After trying a number of options that I could not get to work, I ended up with langdetect and it did a pretty good job.
Tip: If Googletrans stoppes working and gives this error 'NoneType' object has no attribute 'group'" , look no further, you made no mistake, update to googletrans 3.1.0a0 or higher. Use "pip freeze" to see your package version. This problem was a real consumer of time, and I solved it only by accident further on in the process.
It is possible to do a lot of data cleaning. I did not, I only removed the @ from the tweets. I did not mind if mentioned twitter names would appear in the word cloud.
After the data cleaning I created a subset of tweets recognized as Dutch or English and used this set for the next round, the actual translation of Dutch tweets.
The sentiment of my tweets, version 2, based on translated Dutch and English tweets
A better version of the sentiment analysis had to be based on translated Dutch (because of Vader) and English tweets. There were about 2400 tweets left. The translation was done before anything Sentiment Analysis related.
The translation
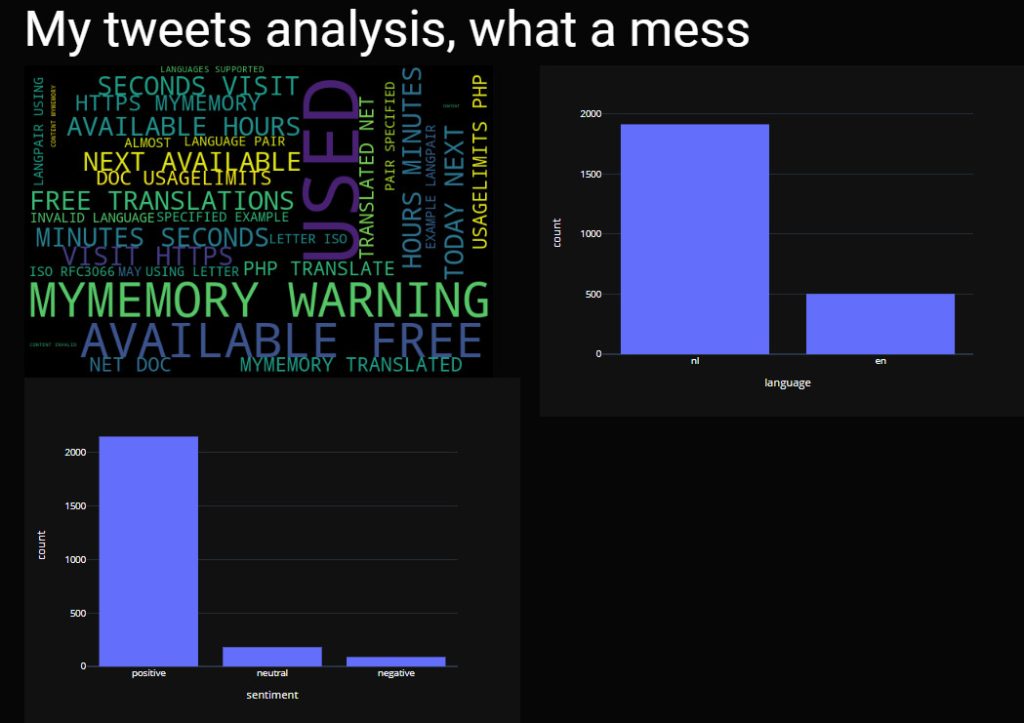
The first route I chose was based on this post and used Memory Translation Service (free as long as you don’t hit the limits).
I hit the limits immediately and it resulted in an interesting word cloud. Neglect the language histogram, it is the before translation situation. It is worthwhile to notice the positive sentiment these error messages generated in the sentiment analysis :
The second translation attempt was “back to googletrans”, which was also when I fixed the bug by an update. The implementation was quick (as was the Memory Translation service implementation).
And the outcome of the sentiment analysis, based on “everything in English”:
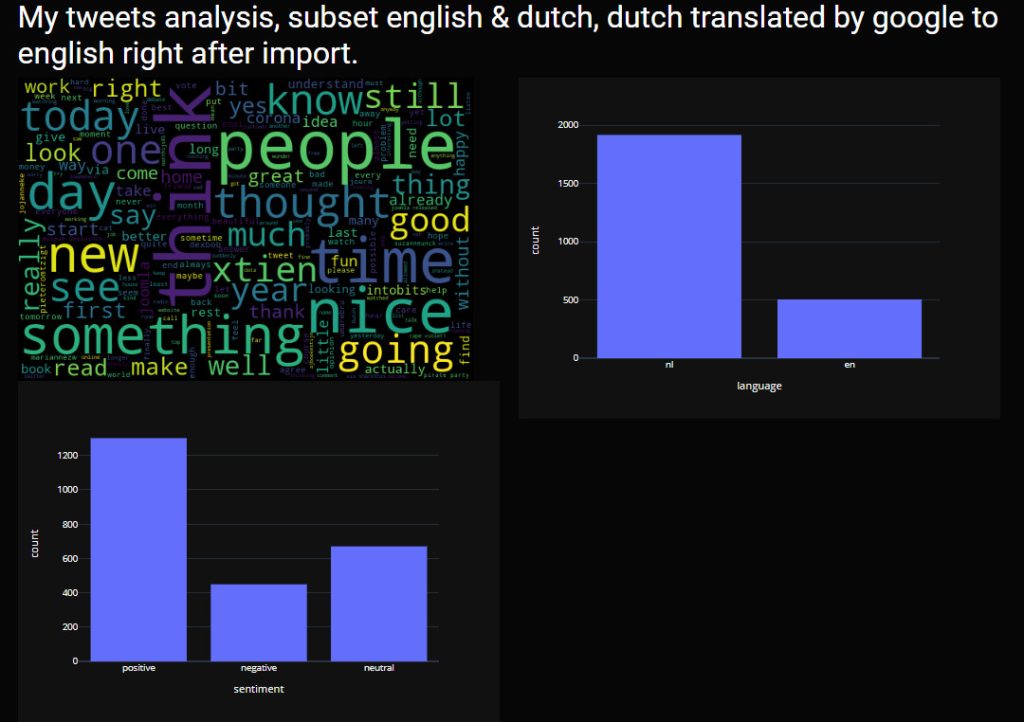
A clear shift from neutral (sentiment analysis on raw data) to positive. I think I agree with the picture, it suits my tweet behaviour. Maybe someday I will dive into the 400 lost tweets. Besides that there are so many things to query left (most data actually) but almost no budget left until the 15th of September.
What took the most time:
- getting the oauth2 authorization working
- googletrans (because I thought it was me) and the solution was not broadcasted on the internet every time the problem was mentioned.
Conclusions
- Garbage in, garbage out, read the documentation, this experiment certainly needs more tweaking.
- Reading the documentation regarding versions of the Twitter API and Oauth versions would probably have saved me some time.
- I am a bit puzzled by the positive outcome of the error message sentiment analysis, the one where I hit the limits of the translation service very quickly. But my initial question was “What if a machine….”, not a human being.
- Kirenz.com is full of clear examples, highly recommended.