Afgelopen maandag las ik een post op LinkedIn waarin stond dat meedoen aan data challenges niet de manier is om je portfolio op te bouwen. Daar ben ik het niet helemaal mee eens. Mijn vader slingerde regelmatig “üben, üben, üben” naar mijn hoofd en elke challenge is een oefening, al is het maar in geduld. Maar goed, iets anders dus. Ik besloot de vraag “stel dat een machine onderzoekt of ik wel een beetje positief ben op twitter door daar een sentiment analyse op los te laten” te beantwoorden. Mijn eigen analyse die mijn tweets indeelt in positief, negatief en neutraal moest het antwoord op de vraag geven.
Ik vond het leuk om deze opdracht met python, dash en plotly aan te pakken. Voor het antwoord alleen had dat niet gehoeven. De vraagstelling leek me redelijk overzichtelijk en googlebaar. Het resultaat was belangrijker dan de lay-out.
Aanpak
De uitgebreide toelichting, met links die ik heel nuttig vond en wat problemen waar ik tegenaan liep, is te vinden onder de blogs. Hieronder in het kort de genomen stappen:
- App aanmaken op deverloper.twitter.com, keys genereren en zoveel mogelijk recente tweets ophalen ophalen (ca. 2800 werden het zonder filtering waar 3200 het maximale resultaat was) met een gratis account via de Twitter API.
- Basis sentiment analyse op met Vader, output in de Spider IDE.
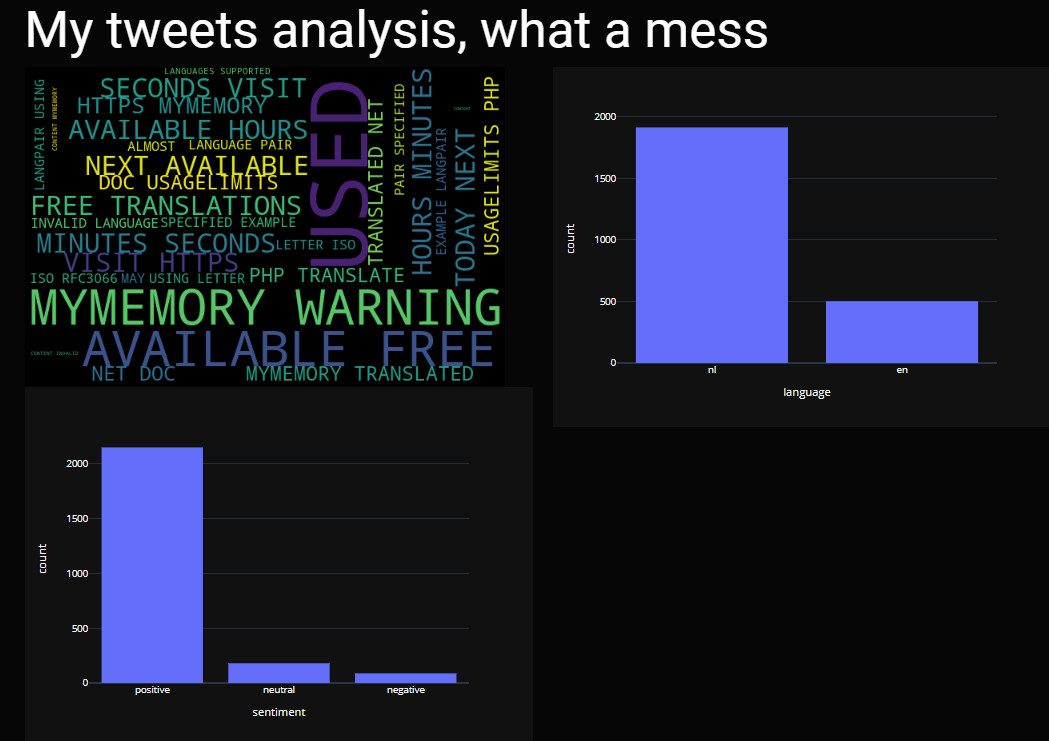
- Converteren output van Spider IDE naar Dash met Plotly (de wordcloud is geconverteerd naar een afbeelding die op het scherm staat omdat Plotly geen wordclouds heeft), zie afbeelding 1.
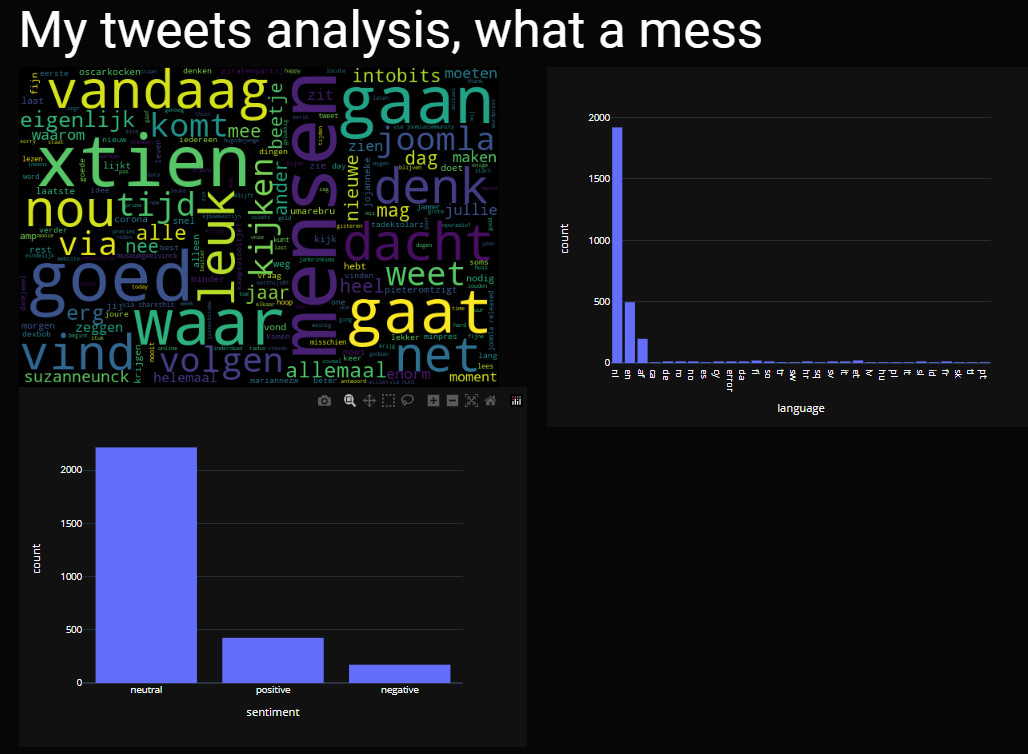
- Taalherkenning bij tweets (ca. 1900 tweets werden herkend als Nederlands, Engelstalig werd redelijk herkend, de rest?)
- Basis data cleaning. Voorbeeld: antwoorden die begonnen met een @ werden o.a. herkend als Afrikaans. Resultaat waren ca. 2400 tweets die NL of EN waren. Deze tweets heb ik gebruikt om te vertalen en voor de laatste analyse.
- Google translate (googletrans) om alle Nederlandstalige tweets te vertalen naar Engelstalig. Afbeelding 2 toont wat je krijgt als de limiet van een vertaalservice eerder is bereikt dan gewenst. De positieve uitkomst van die analyse is curieus.
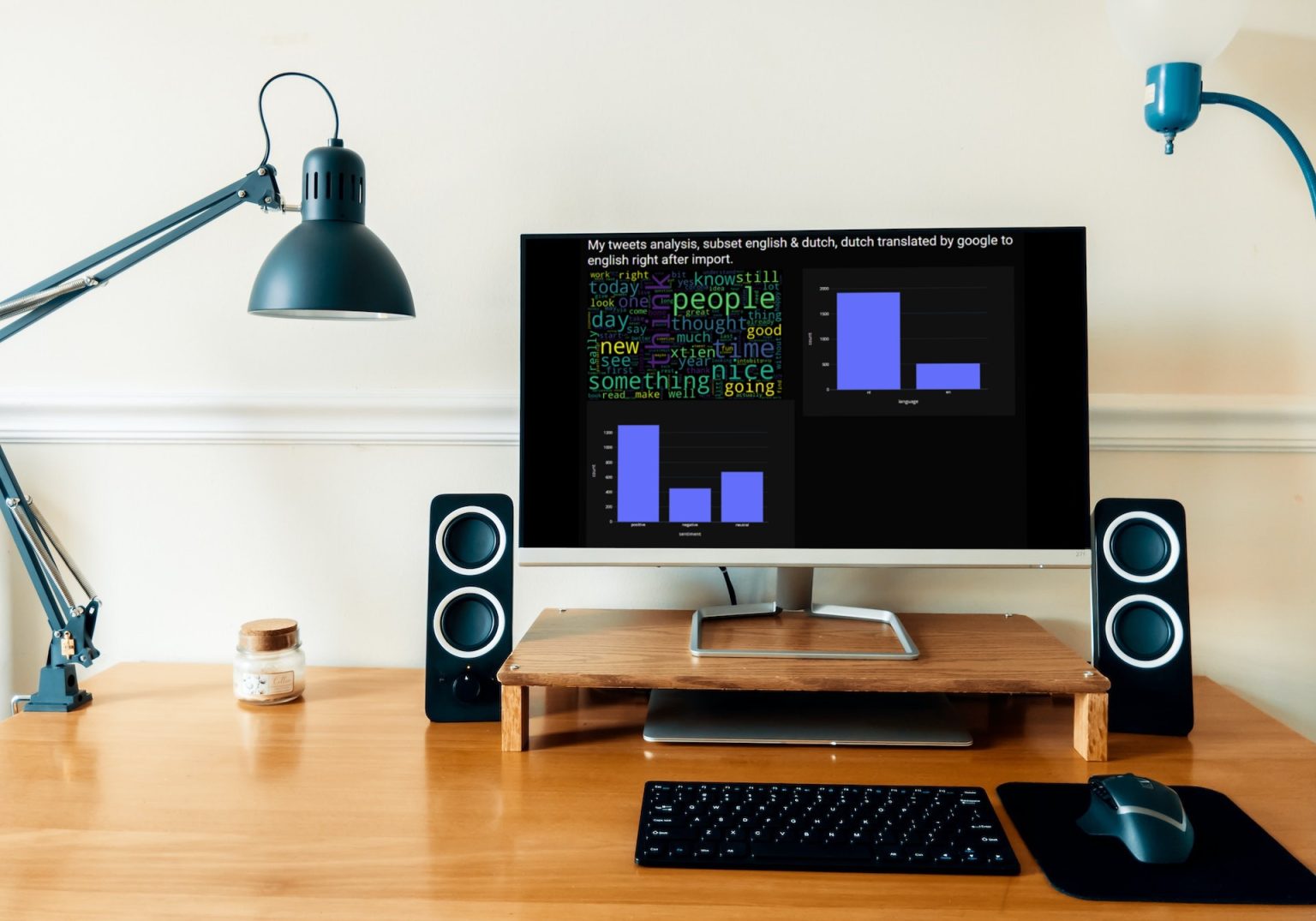
- Uiteindelijke analyse op basis van 2400 tweets voorzover nodig vertaald naar het Engels. Zie afbeelding 3.
Samengevatte aanpak: zorg dat je eerst een werkende pipeline hebt met een resultaat en ga dan inzoomen op de problemen.
Resultaat
Op de afbeeldingen is linksboven de tagcould te zien met meest populaire woorden (en soms mensen) in mijn tweets, rechtsboven het resultaat van taalherkenning en linksonder het uiteindelijke resultaat van de sentiment analyse uitgevoerd op vertaalde nederlandstalige en engelse tweets.
Het resultaat van deze exercitie maakt duidelijk dat “garbage in/garbage out” ook hier opgaat. In het uiteindelijke resultaat, afbeelding 3, kon ik me vinden. Meestal laat ik niet al te constructieve reacties in mijn hoofd en gooi ze niet op Twitter. De code is op Github te vinden. Het blijft natuurlijk interessant wat er in de 400 niet gebruikte tweets stond, dat waren niet alleen Wordle scores. Globaal, de titel zegt het al. Voorlopig is mijn gratis developerbudget bij Twitter op (dat ging harder dan ik verwachtte), er zijn genoeg aanknopingspunten om hier dieper in te duiken en misschien doe ik dat nog wel eens.